Research Areas
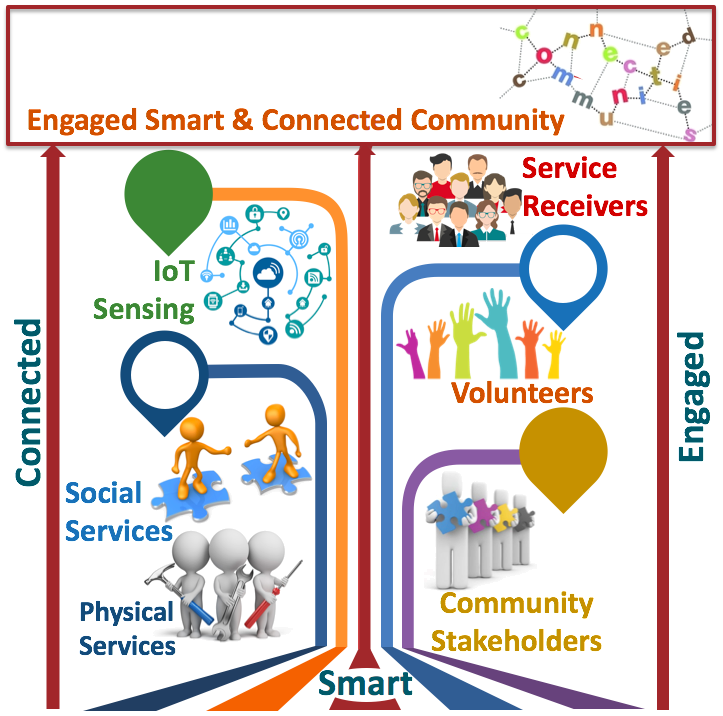
Socially Important Data Science
Data science is a truly interdisciplinary field related to data mining, machine learning, and big data. Understanding and solving real--world social problems, requires (i) comprehending how theory--informed methods, models and algorithms can be applied to messy, unstructured, sparse, and noisy data in the real--world, (ii) understand the limitations, and (ii) derive socially informed methods working closely with domain exteprts (including nonprofits, human service providers, transportation experts, government agencies and more). Details available here.
ICDMW 2017; Asilomar 2018; ASONAM 2018; ICASSP 2018; BigData 2018; GlobalSIP 2018; Asilomar 2019; ASONAM 2019; BigData 2019; ICASSP 2019; WebSci 2019; TheWebConf 2019; ICASSP 2020; MLSP 2020; TITS 2020; JSSR 2020; CAS 2021; DSSGW 2021; NetSci 2021; TWeb 2021; ASONAM 2021; BigData 2021; TAI 2021; ASONAM 2022; BigData 2022; JCSS 2023; SNAM 2023; ICASSP 2023; TAI 2023; ICWSM2023; TCSS 2023; BigData 2023
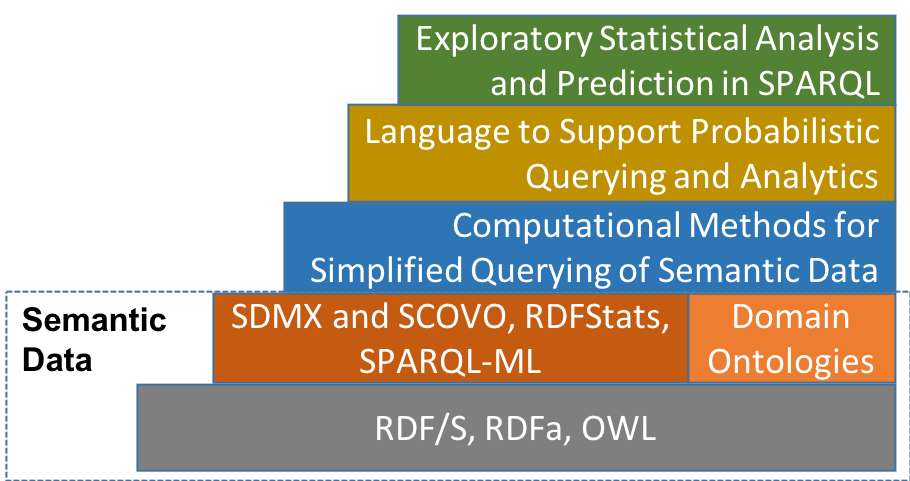
Democratizing the Semantic Web
Search engines, virtual assistants and other recent technologies rely on semantic data, which remain largely inaccessible to those unfamiliar with Semantic Web Technologies, standards, and protocols, data formats, and query languages. Our goal is to reduce the effort and expertise required to access and analyze semantically enriched data, and therefore democratize the use of such data. Details here.
IJCAI 2016; US Patent App. 15/701,160; Managing the Web of Things 2017; AI Communications 2018; SemWeb 2019; CAS 2021; ICWSM 2023
Past Projects
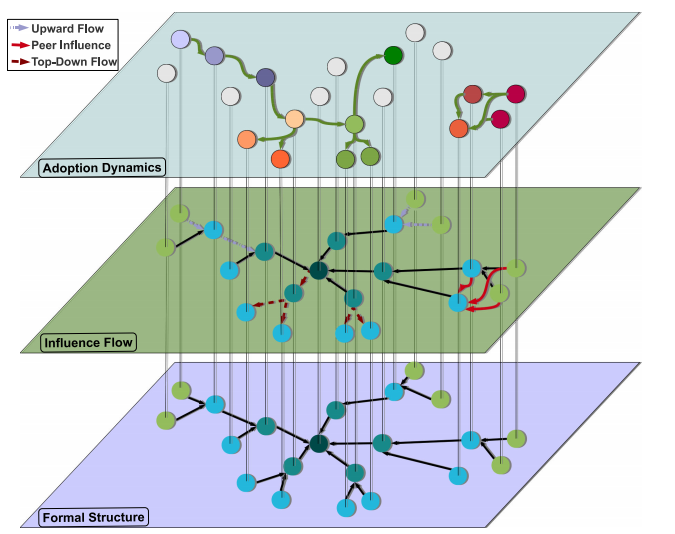
Using Big Data to Understand Social Behavior
Several models on the flow of information in online social networks have been proposed in the literature. Such models assume that either the spreading process takes place on an unsigned network or that there is only one process unfolding over the network of ties. In reality however, people trying to decide whether to adopt an innovation, a political idea, or a product are frequently influenced by a variety of factors. We have introduced and continue to develop a unified model that enables the realistic modelling and accurate prediction of diffusion in networks.
SocialCom 2011; ASONAM 2012 (2); SocialCom 2012; JCI 2013; MSM 2013; TOIS 2013; SNAM 2013; ASONAM 2013 (2); SNAM 2014; ASONAM 2014; SNAM 2015; ASONAM 2015; WWW 2015; SNAM 2016; NetSci-X 2016; WebSci 2017; BigData 2019; ASONAM 2019
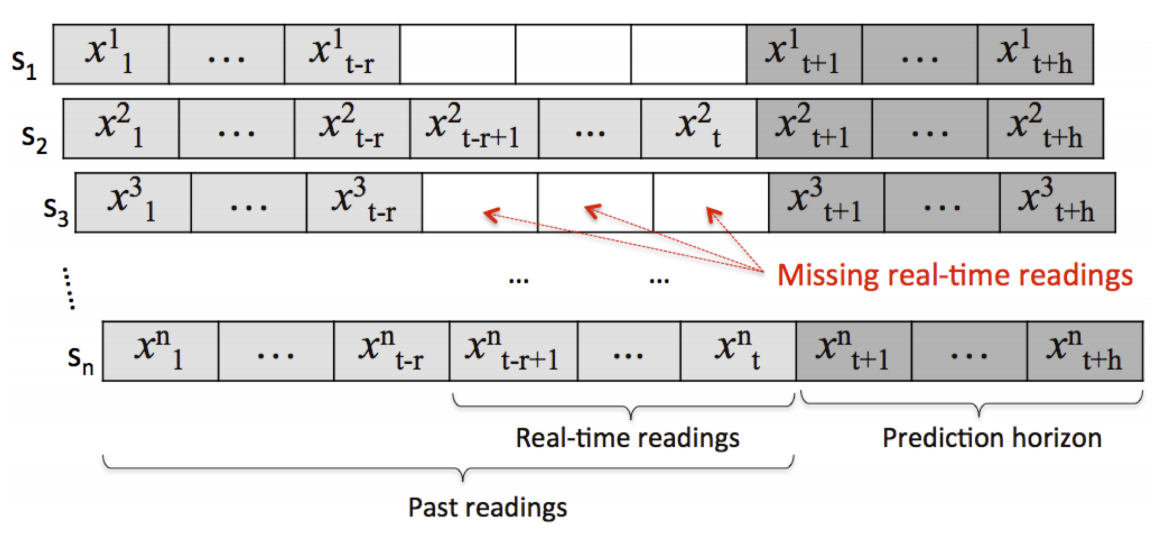
IoT-Generated Big Data Informatics
Recent studies have shown that 2.5 quintillion bytes of data is being generated per day and this is set to explode by 2020. Much of this data is and will be generated from Internet of Things (IoT) devices such as sensors in Smart Cities and Smart Energy Grids, and smart consumer appliances or social media. To address the challenges associated with the real--time exploration, mining, and analytics of big data, we are working towards developing novel capabilities that will facilitate the integration and querying of numerous and dynamic data streams, large repositories of historical data, and static knowledge to support meaningful pattern and connection discovery for near real-time decision making.
IGCC 2014; Big Data 2014 (2); e-Energy 2015 (3); IGI 2015; Big Data 2015; AAAI 2015 (2); SPE IE 2016; FTC 2016; WF-IoT 2016; ICCS 2016; TPDS 2016; AAAI 2016; IJCAI 2016; PES ISGT 2017
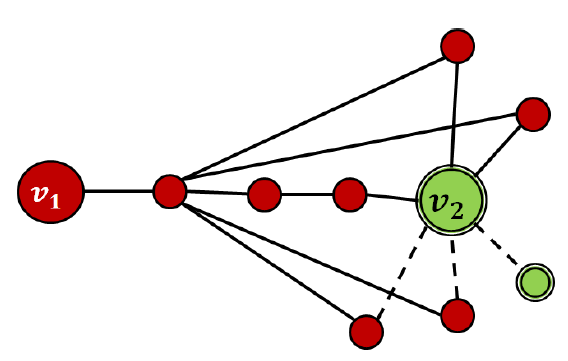
Relative Importance of Nodes in Networks
In graph theory, identifying the most important vertices within a graph implies the use of a centrality metric. Applications include identifying the influential users in a social network, key infrastructure nodes in the Internet, and disease spreaders. Over the years, a variety of centrality metrics have been proposed to measure the relative importance of nodes based on the network structure. Motivated by the need to identify "influential" nodes and study their role in the flow of diseases in epidemiology and information in social networks, we have devised and continue to develop niche centrality metrics based on diffusion dynamics over networks.
SNAM 2016; HPEC 2017; AAMAS 2018
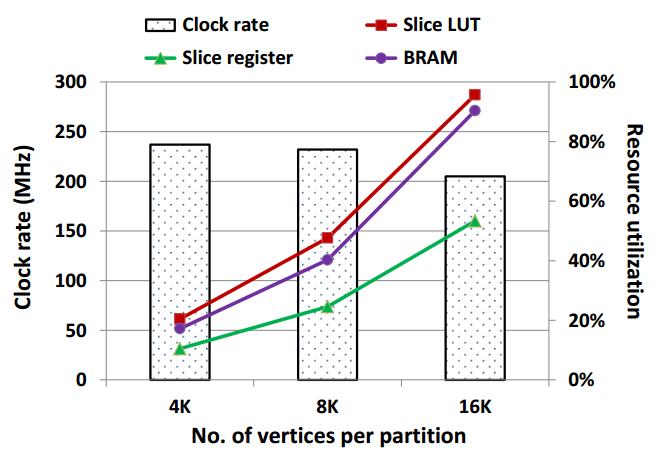
Big Data with Structure on Hardware Steroids
Computational resources have been unable to keep up with the vast amounts of data which keep piling up at staggering velocities. Yet, querying and analysis of Big Data has become critical for data-enabled scientific discovery. To address the dark silicon challenge, we are pairing conventional CPUs with massively parallel accelerators such as field-programmable gate arrays (FPGA) and emerging memory technologies and developing novel energy-efficient and massive parallel algorithms capable of handling not only the size, and rate of Big Data, but also the corresponding heterogeneity in the compute fabric and the memory hierarchy.
ReConFig 2015 (2); IPDPS 2015 (2); CCGrid 2015; FCCM 2016; BigData 2016; HPEC 2017