Project Description
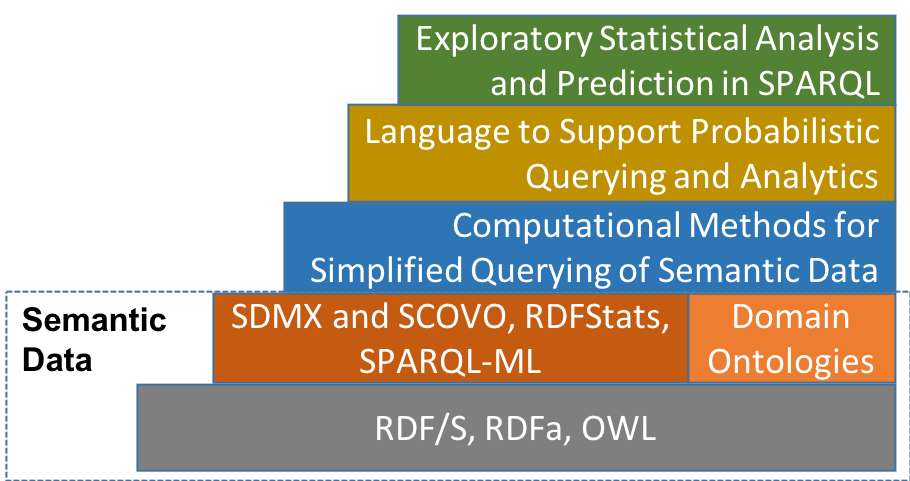
Search engines use semantic annotations to provide search results, which remain well hidden behind the familiar search box interface. Beyond web search and recent technologies such as virtual assistants, semantically enriched data appear in a wide spectrum of application domains, including but not limited to, bioinformatics, neuroscience, health care, and social and psychological sciences. Access to semantic data, however, has been restricted to those intimately familiar with Semantic Web Technologies, standards, and protocols, data formats, and query languages. This project aims to substantially reduce the effort and expertise required to access and analyze semantically enriched data, and therefore increase the range of applications that can benefit from such data.
The technical aims of this NSF funded project are divided into two thrusts. The first thrust focuses on developing a general approach to support simple and intuitive, yet functional, visual semantic querying. In particular, algorithms are devised to automatically construct semantic queries from keywords provided through a search-like interface. The second thrust focuses on enabling the statistical exploration, analysis, and predictive modeling of semantic data. Specifically, new primitives based on ideas from statistics and information theory are to be incorporated directly into SPARQL, the query language for retrieving, and discovering relationships from semantic data. An ontology will be designed to support alternative statistical operations. Computational methods and algorithms for query answering in this setting are under development.
Project Personnel
This project involves Prof. Chelmis and students from the College of Engineering & Applied Sciences at the University at Albany, State University of New York (SUNY).
- Akshay Gujjari, M.S. in Computer Science
- Ujash Dharmen Modi, M.S. in Computer Science
- Santhosh Ranganathan, M.S. in Computer Science
Code And Documentation
To promote the reproducibility and replicability of our work, and to enable fundamental research and collaboration across disciplinary, organizational, and geographical boundaries, we will make the source code of the algorithms genrated by this research publicly available through our Github repository. User documentation will be part of our software releases.
Publications
For an up-to-date list of our publications, please contact Prof. Chelmis.
- M. R. Saeed, C. Chelmis, and V. K. Prasanna, "Extracting entity-specific substructures for RDF graph embeddings" Semantic Web 10.6 (2019): 1087-1108.[pdf]
- M. R. Saeed, C. Chelmis, and V. K. Prasanna, "ASQFor: Automatic SPARQL query formulation for the non-expert." AI Communications 31.1 (2018): 19-32.[pdf]
- M. R. Saeed, C. Chelmis, and V. K. Prasanna, "Thou Shalt ASQFor and Shalt Receive the Semantic Answer" IJCAI. 2016. [pdf]
- M. R. Saeed, C. Chelmis, and V. K. Prasanna, "Automatic Integration and Querying of Semantic Rich Heterogeneous Data: Laying the Foundations for Semantic Web of Things" Managing the Web of Things. Morgan Kaufmann, 2017. 251-273. [pdf]
Educational Activities and Outreach
The nature of this project enables novel educational opportunities related to semantic web technologies, data mining, and statistics. The PI is currently developing a new course on foundations, techniques, and algorithms for information integration, management and querying using Semantic Web technologies, which is currently lacking from the curriculum of the Computer Science Department. Through this course, students will have the opportunity to develop critical skills and hands–on experience with collecting, modeling, and analyzing real–world semantic datasets.Contact Information
If you interested in joining our efforts or have questions about our research, you can reach out to the PI of this project as follows:
Charalampos Chelmis
Assistant Professor
IDIAS Lab
Computer Science Department
College of Engineering and Applied Sciences
University at Albany State University of New York (SUNY)
1215 Western Ave, UAB 424B, Albany, NY 12222.
Ph: (518) 437-4948 | Fax: (518) 437-44949 | E-Mail: cchelmis [at] albany [dot] edu
Web page: https://www.cs.albany.edu/~cchelmis/
Acknowledgment
This material is based upon work supported by the National Science Foundation under Grant Number 1850097. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.

